|
大数据时代来了。当所有人都争吵着这件工作的时候,当所有企业都看好大数据的成长前景的时候,却都很少存眷这些数据从哪儿来,我们有没有足够优秀的技能本领处理惩罚这些数据。 联网设备增加 数据量随之上升 网络的成长无疑为我们迎接大数据时代、智能计较时代铺好了路。按照研究公司的预测,全球联网设备正在增加,在部门国度,人均联网设备早已高出2台;如此大量的联网设备和不绝提高的网络速度都在让社会的数据量快速增长,伶俐都市、平安都市的实现也是以视频监控等视频数据为基本,成为大数据时代的重要构成部门。 呆板人、AI、呆板进修的研究让数据成为将来帮助我们糊口的须要因素,无人车、呆板人快递等形式的呈现, 一方面浮现了数据代价,另一方面也是在不绝收集数据,反哺数据阐明和应用。 数据体量太大 谁来处理惩罚? 数据发生后,意味着数据的收罗事情已经完成,那么数据的输入与有效输出问题怎么破解? 自大数据时代到来之后,漫衍式存储、大文件的读写都成为热点话题,如何应对越来越多的大文件存储、阐明与检索,成为企业需要攻陷的困难。
而Hadoop的原型要从2002年开始说起。Hadoop的雏形始于2002年的Apache的Nutch,Nutch是一个开源Java 实现的搜索引擎。尔后按照谷歌颁发的学术沦为谷歌文件系统(GFS),实现了漫衍式文件存储系统名为NDFS。尔后又按照Google颁发的一篇技能学术论文MapReduce,在Nutch搜索引擎实现了用于大局限数据集(大于1TB)的并行阐明运算。最后,雅虎招聘了Doug Cutting,Doug Cutting将NDFS和MapReduce进级定名为Hadoop,HDFS(Hadoop Distributed File System,Hadoop漫衍式文件系统)就此形成。 应该说Hadoop是针对大数据而存在的,HDFS可以或许提供高吞吐量的数据会见,适合有着超大局限数据集的应用措施。我们可以在Hadoop的设计中看到三大特点:合用于存储超大文件、适合运行在普通便宜的处事器上,同时,最搞笑的会见模式是一次写入、多次读取。
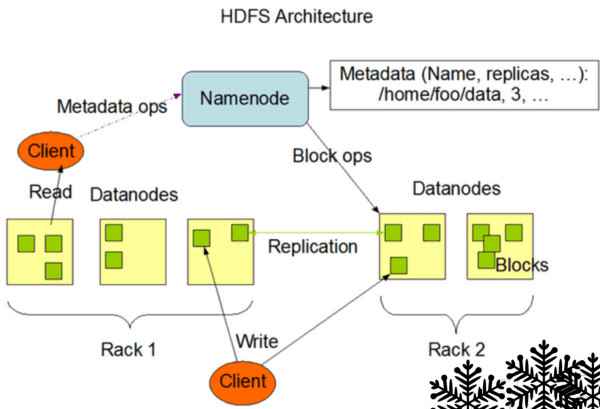
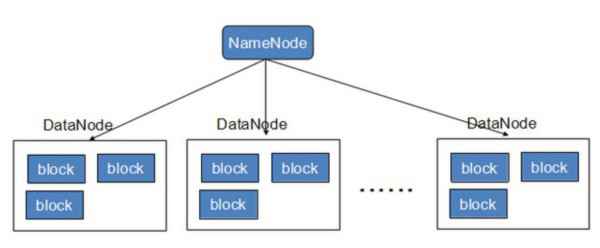
虽然,HDFS也存在一些漏洞,好比说不合用于有低延迟要求的应用场景。因为Hadoop是针对大数据传输的存在,是为高数据吞吐量应用而设计,这导致其一定要以高延迟作为价钱。同时HDFS漫衍式存储不合用于小文件传输,在大量小文件传输进程中,namenode的内存就吃不用了。 Hadoop观念科普 在相识了Hadoop的出身和此刻适合的应用场景之后,笔者要跟各人科普一下Hadoop的基本架构和主要观念。 NameNode:namenode认真打点文件目次、文件和block的对应干系以及block和datanode的对应干系。这是由独一一台主机专弟子存,虽然这台主机假如堕落,NameNode就失效了,需要启动备用主机运行NameNode。 DataNode:认真存储,虽然大部门容错机制都是在datanode上实现的。漫衍在便宜的计较机上,用于存储Block块文件。 MapReduce:通俗说MapReduce是一套从海量·源数据提取阐明元素最后返回功效集的编程模子,将文件漫衍式存储到硬盘是第一步,而从海量数据中提取阐明我们需要的内容就是MapReduce做的事了。 Block:也叫作数据块,默认巨细为64MB。每一个block会在多个datanode上存储多份副本,默认是3份。 Rack:机柜,一个block的三个副本凡是会生存到两个可能两个以上的机柜中。 |